
TesfriX
Présentation du projet
TesfriX est un projet ambitieux développé par Innlog, une filiale du Groupe Tesson, spécialisée dans les logiciels de gestion logistique. Conçu comme une refonte complète du WMS Tesfri, il vise à offrir une solution intégrée et modulaire adaptée aux besoins des entreprises modernes. Initialement limité à la gestion des stocks et des flux de marchandises, Tesfri a évolué pour répondre aux exigences accrues des entreprises, qui recherchent des solutions globales comme les ERP intégrant plusieurs domaines métiers, notamment la gestion commerciale et le contrôle financier.
Pour y parvenir, TesfriX repose sur une architecture modulaire, permettant aux entreprises d’activer uniquement les fonctionnalités nécessaires, garantissant ainsi une personnalisation avancée et une gestion optimisée des ressources. Cette approche offre plusieurs avantages : une mise à jour indépendante des modules sans impacter l’ensemble du système, une plus grande flexibilité et une meilleure agilité pour les équipes de développement. Chaque module, qu’il concerne la gestion des stocks, le suivi des commandes ou encore le contrôle de gestion, dispose de son propre projet front-end et back-end, assurant ainsi un cloisonnement efficace et une évolution progressive des fonctionnalités.

L’un des premiers modules intégrés à TesfriX est celui du contrôle de gestion, présent dans le domaine supervision. Celui-ci joue un rôle essentiel dans l’optimisation des performances financières et opérationnelles des entreprises. En s’appuyant sur des outils d’analyse des coûts, de suivi des écarts et de planification budgétaire, ce module permet aux entreprises de structurer leur prise de décision et d’orienter efficacement leurs stratégies. En intégrant ces fonctionnalités, TesfriX ne se contente plus de gérer les flux logistiques, mais devient un véritable levier de compétitivité, offrant une vision globale et précise des données essentielles à la gestion d’une entreprise.
Toujours en cours de développement, TesfriX marque une avancée significative dans la gestion des flux logistiques et industriels. Grâce à son architecture évolutive et intégrée, il s’impose comme un ERP performant et flexible, capable de s’adapter aux défis des entreprises modernes en leur proposant une solution complète et personnalisable.
Objectifs
L’objectif de cette réalisation est de mettre en place, au sein du domaine supervision de TesfriX, un système de gestion des imports de données provenant de l’application tierce Sage. Ce besoin est essentiel pour permettre aux entreprises utilisant TesfriX d’intégrer efficacement leurs données comptables et financières, tout en garantissant leur traçabilité et leur fiabilité.
Le projet vise à concevoir un processus d’importation structuré, capable de traiter de grands volumes de données, tout en assurant une cohérence entre les informations importées et celles déjà présentes dans le système. Pour cela, une architecture hybride a été mise en place, combinant un stockage non relationnel destiné aux fichiers bruts et un stockage relationnel permettant d’organiser et d’exploiter les données importées.
Un autre objectif clé est la mise en place de mécanismes de validation, permettant de filtrer les erreurs potentielles et de contrôler les droits d’accès en fonction des utilisateurs. L’enjeu est d’éviter l’intégration de données corrompues ou incomplètes, tout en offrant une gestion fluide et intuitive des imports.
Enfin, afin d’optimiser l’utilisation des données intégrées, plusieurs fonctionnalités complémentaires ont été développées, comme l’exportation des fichiers, la suppression sélective des données, et un suivi avancé des imports validés. Ces outils visent à faciliter l’exploitation des informations comptables au sein de TesfriX, tout en garantissant une gestion optimisée des flux de données provenant de Sage.
Enjeux de la réalisation
L’intégration de Sage dans TesfriX pose plusieurs enjeux techniques et organisationnels. Le premier concerne l’intégrité et la cohérence des données : toute erreur dans l’importation ou le traitement peut compromettre la fiabilité des informations utilisées par l’application. La gestion des performances est également un point clé, le volume important de données pouvant générer des ralentissements si l’optimisation des traitements et des requêtes n’est pas rigoureuse.
L’interopérabilité entre Sage et TesfriX représente un autre défi. Les deux systèmes ayant des modèles de données distincts, il est nécessaire d’adapter les structures et les formats pour éviter les incompatibilités. L’automatisation du processus d’importation et de validation doit ainsi être suffisamment flexible pour absorber les différences, tout en garantissant une cohérence globale.
Enfin, l’adoption par les utilisateurs est un enjeu majeur. Les fonctionnalités d’importation et de validation doivent être accessibles et intuitives, sans quoi leur adoption risque d’être limitée, freinant ainsi l’efficacité du processus. Une interface trop complexe ou des validations trop rigides pourraient entraîner un rejet du système, nécessitant un travail d’amélioration continue et d’accompagnement des utilisateurs.
Risques et contraintes
L’un des principaux risques du projet réside dans la sécurité des données. L’importation de fichiers implique la manipulation d’informations sensibles, ce qui nécessite des mécanismes robustes de contrôle des accès et de chiffrement pour éviter toute fuite ou corruption des données. Une faille à ce niveau pourrait compromettre la confiance des utilisateurs et impacter la fiabilité du système.
La charge du système est un autre facteur à surveiller. Si les volumes d’importation deviennent trop importants sans optimisation adéquate, cela pourrait entraîner une dégradation des performances et des ralentissements. Une gestion rigoureuse des ressources est donc essentielle pour assurer une exécution fluide, notamment en répartissant intelligemment les traitements et en optimisant les requêtes.
Enfin, la maintenabilité et l’évolutivité du code sont des points à anticiper. Une architecture mal pensée pourrait rendre les futures évolutions complexes, notamment en ce qui concerne l’ajout de nouvelles sources de données ou l’amélioration des validations. Un travail de structuration dès la conception est indispensable pour éviter un code rigide et difficile à faire évoluer.
Ma position dans le projet
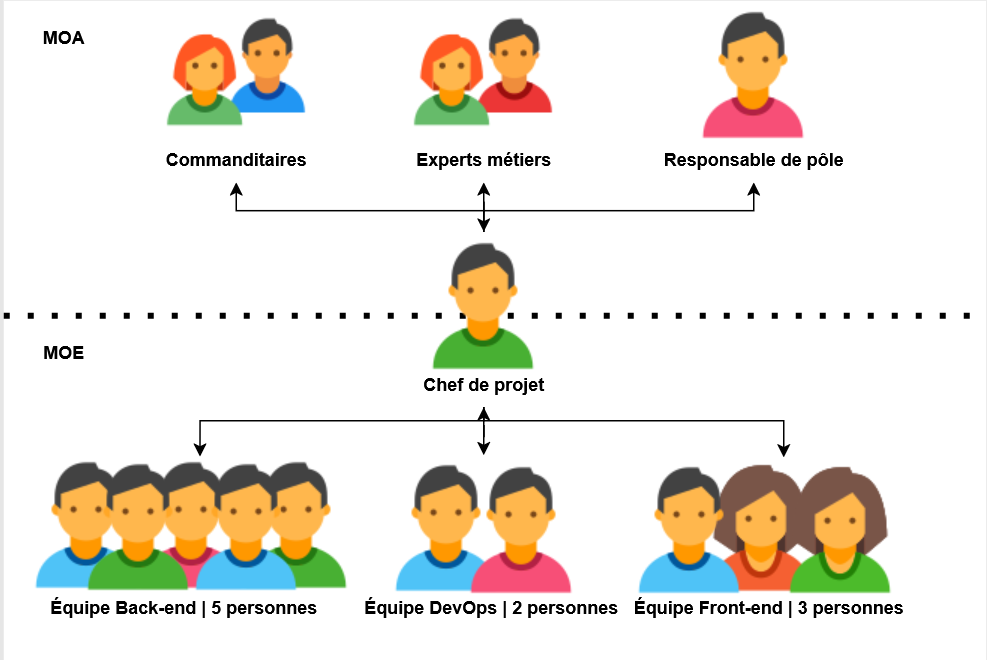
Dans le cadre du projet TesfriX, j’évolue au sein du Pôle Supply Chain, plus précisément dans l’équipe de développement dédiée aux produits. Ce pôle regroupe une cinquantaine de personnes, chacune ayant ses propres missions, contraintes et responsabilités, apportant ainsi une réelle valeur ajoutée à l’ensemble du secteur. Néanmoins, l'équipe correspondant à mon projet ne compte que 13 personnes, dont certaines d'entre elles naviguent entre plusieurs rôles, tels que du développement applicatif et opérationnel.
En ce qui me concerne, je suis alternant en développement front-end et back-end, tout en étant impliqué dans les tâches DevOps. Mon rôle englobe la conception des interfaces utilisateur, le développement des processus back-end et la gestion des infrastructures. J’interviens également dans la mise en place de pratiques d'intégration continue, garantissant ainsi des outils et des systèmes de déploiement automatisés et performants.
Mise en œuvre
Information
Avant d’aborder cette réalisation, il est important de souligner qu’elle m’a permis d’approfondir et de mettre en pratique plusieurs compétences techniques et humaines. Certaines d’entre elles sont détaillées dans d’autres sections de ce portfolio. Si certaines explications vous semblent trop succinctes, je vous invite à vous y référer pour une meilleure compréhension.
Première tâche - Maquettage
La première tâche qui m’a été confiée consistait à réaliser les maquettes de l’application afin de définir son interface et son ergonomie. Pour mener à bien cette mission, j’ai travaillé en étroite collaboration avec mon chef de projet, ce qui m’a permis d’évoluer dans un cadre structuré tout en bénéficiant de ses retours et orientations. Ensemble, nous avons défini les exigences et les attentes de cette fonctionnalité en prenant en compte les besoins des utilisateurs. Cette approche collaborative m’a non seulement aidé à produire des maquettes fidèles aux objectifs du projet, mais elle m’a également permis de développer mes compétences.
Ce travail s’est inscrit dans une réflexion plus large sur l’ergonomie et la lisibilité des données, en lien avec les exigences du module Supervision. J’ai structuré les différentes vues en m’appuyant sur la charte graphique du projet, tout en intégrant une logique modulaire : les maquettes ont été pensées par blocs fonctionnels réutilisables, dans une optique de cohérence avec les autres modules de l’application. Cette approche a favorisé une homogénéité visuelle et fonctionnelle, tout en anticipant les futures interactions front/back. L’ensemble a été conçu pour s’adapter aux contraintes de l’environnement industriel dans lequel TesfriX est déployé.
Présentation des Maquettes
Les maquettes présentées ci-dessous traduisent de manière concrète les choix d’interface et d’interaction retenus pour le module Supervision. Ce cadre commun m’a permis de m’appuyer sur une bibliothèque de composants existants, assurant une parfaite cohérence graphique avec les autres modules de l’application. L’objectif était de proposer un rendu fidèle à l’interface finale, tout en anticipant l’intégration dans l’environnement de production.
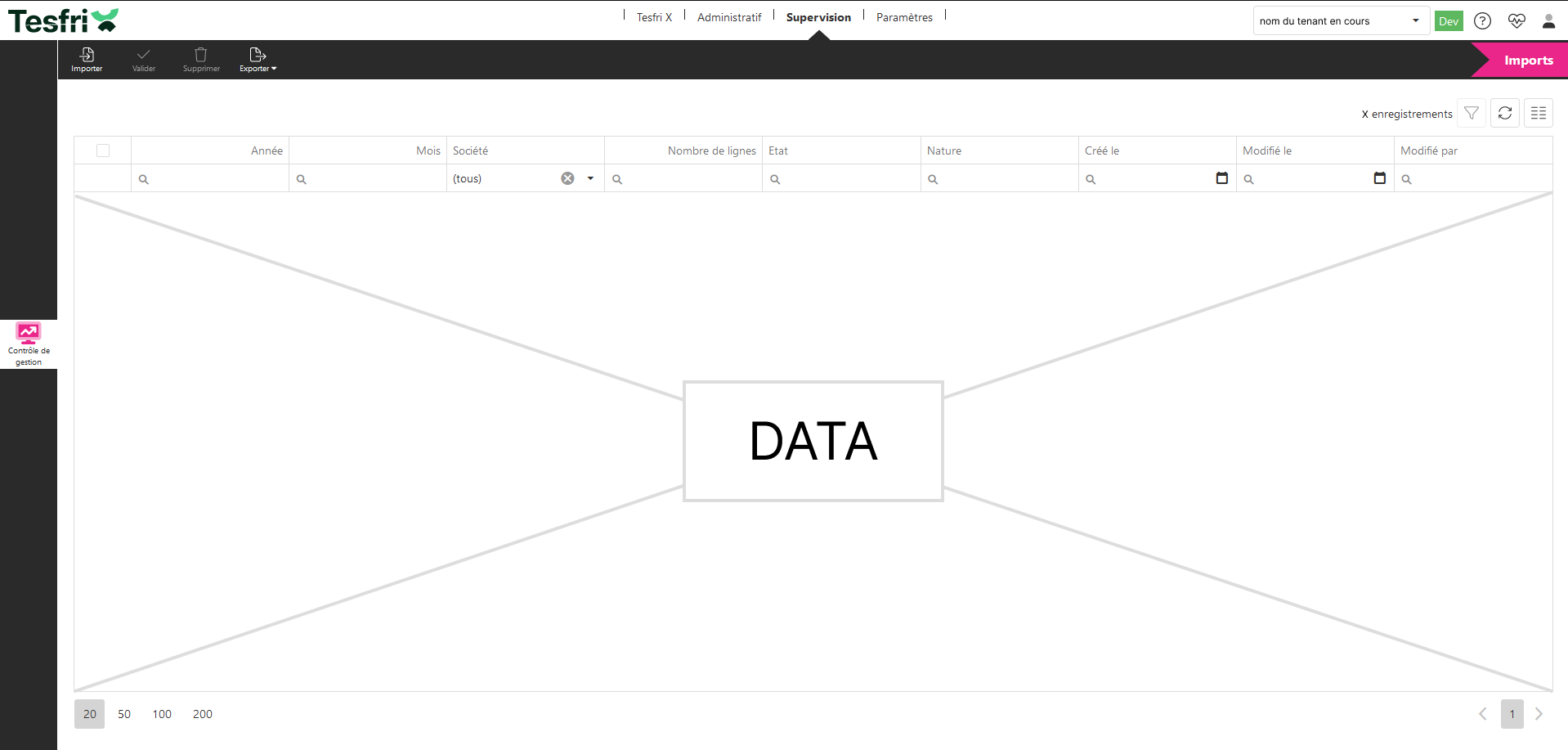
Gabarit de l’écran
L’écran principal repose sur un tableau central listant les fichiers importés, enrichi de filtres pour faciliter la recherche (année, société, état…). Un bandeau supérieur regroupe les actions disponibles (import, validation, suppression, export), accessibles à tout moment.
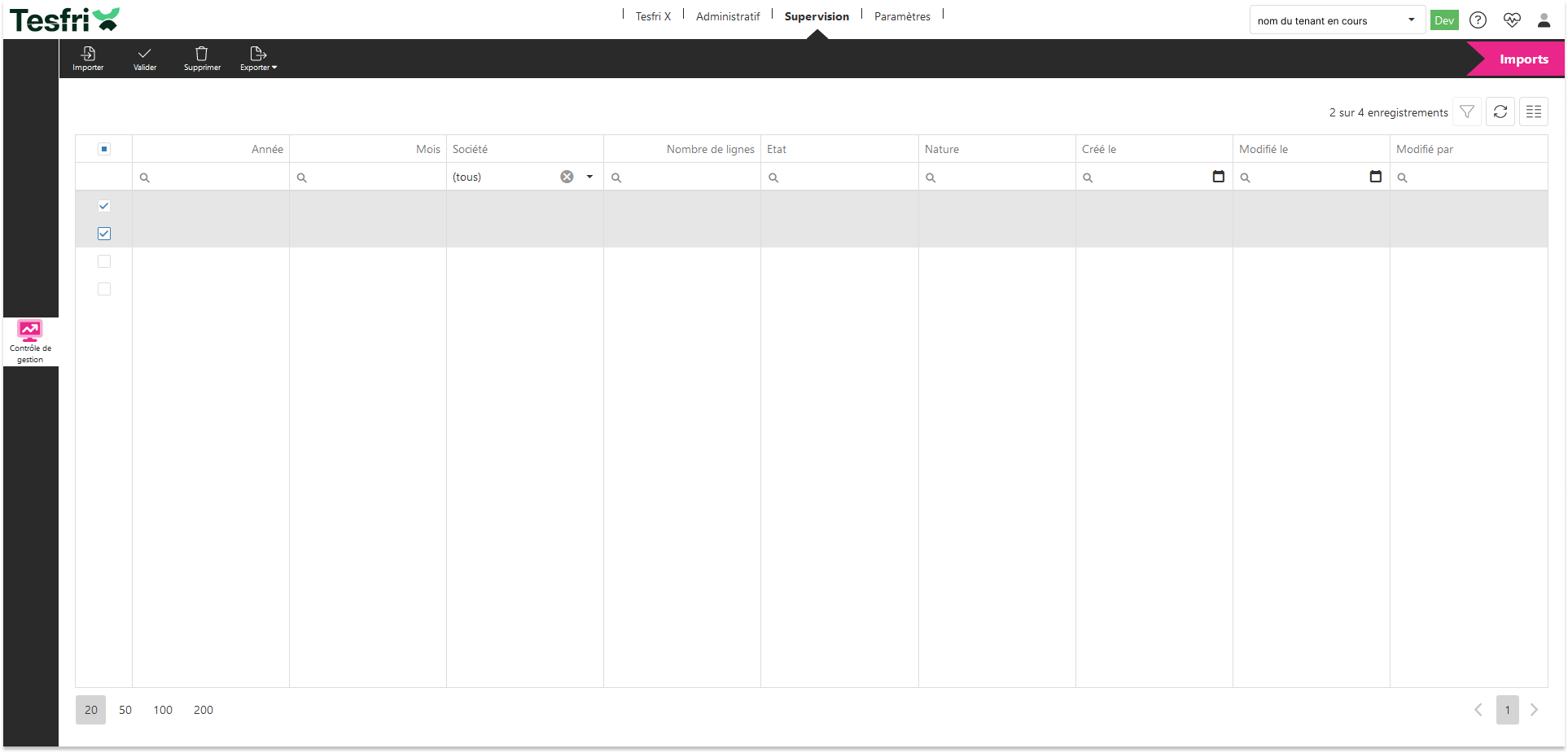
Comportement de la sélection
Lorsqu’une ou plusieurs lignes sont sélectionnées, des actions groupées deviennent disponibles. Ce fonctionnement améliore l'efficacité de traitement et permet de valider ou supprimer plusieurs imports en un clic, tout en offrant un retour visuel clair.
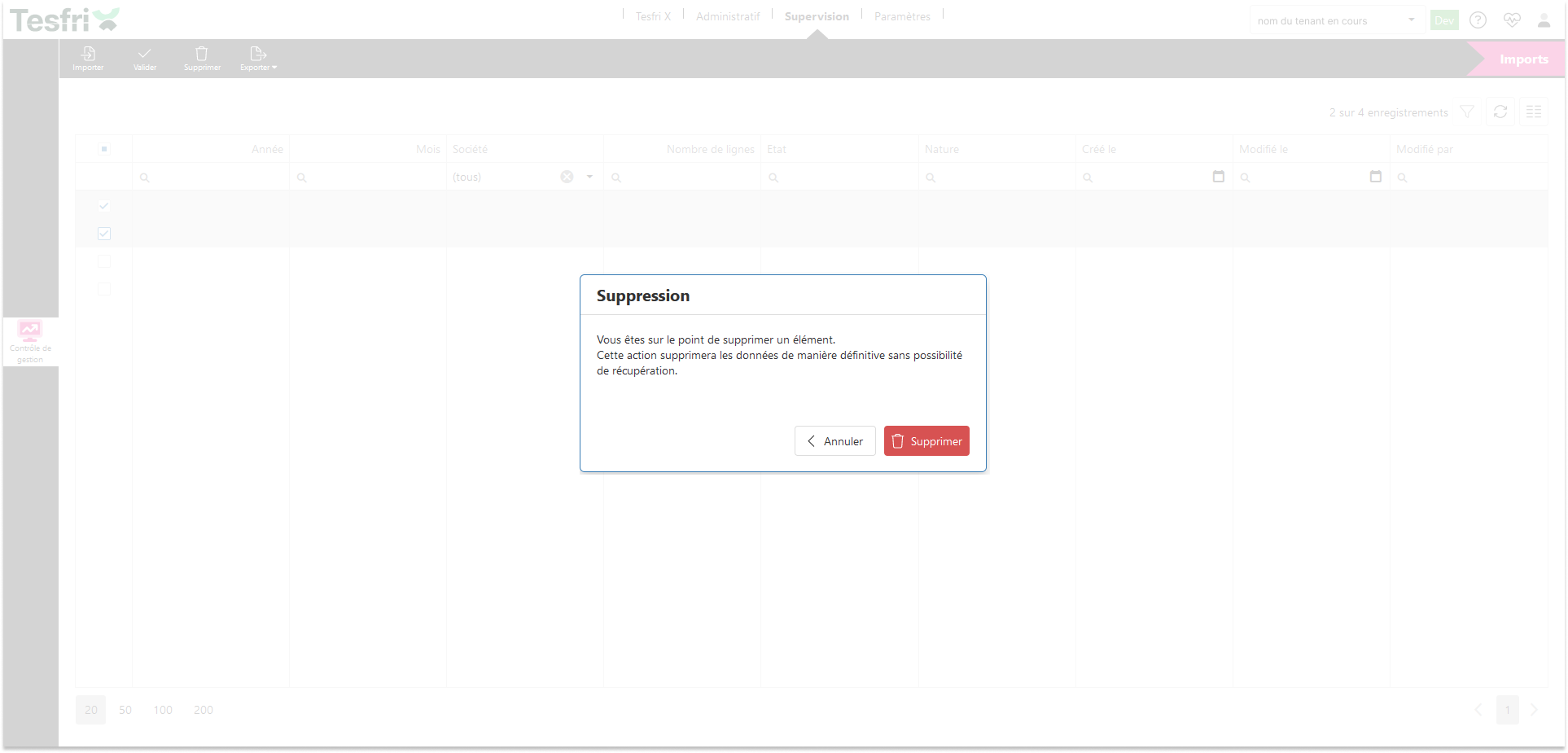
Vérification de suppression de la sélection
Avant toute suppression définitive, une fenêtre de confirmation s’ouvre pour éviter les erreurs de manipulation. Le design sobre et contrasté attire l’attention sur le caractère irréversible de l’action, renforçant la sécurité d’usage.
Explication des Maquettes
Pour concevoir ces maquettes, j’ai utilisé l’application Web Figma, un outil collaboratif permettant de créer des interfaces interactives et de les partager avec les équipes. L’objectif principal du maquettage est de fournir une vision claire et anticipée du rendu final de l’application avant le développement, en s’assurant qu’il réponde aux besoins fonctionnels identifiés lors de l’analyse préalable.
L’interface conçue repose principalement sur un tableau central, qui constitue l’élément clé de la gestion des fichiers importés. Ce tableau permet d’afficher les informations essentielles pour chaque fichier, notamment :
- Le mois et l’année de compatibilité,
- L’entreprise associée,
- Le nombre de lignes contenues dans le fichier,
- L’état de validation de l’import,
- La nature du fichier (simulation ou réel).
Pour garantir une interactivité fluide, plusieurs actions ont été intégrées et accessibles via un menu de commandes situé dans la partie supérieure de l’écran.
- Importation des fichiers : Cette fonctionnalité permet à l’utilisateur de sélectionner des fichiers via l’explorateur Windows afin de les importer dans l’application. Les fichiers proviennent du logiciel Sage, un outil de gestion largement utilisé par les entreprises.
- Validation des imports : Une fois les fichiers importés, il est nécessaire de les valider avant qu’ils puissent être exploités. Cette action s’applique à une ou plusieurs lignes sélectionnées dans le tableau.
- Suppression des fichiers : Un fichier importé peut être supprimé si l’utilisateur en fait la demande. Pour éviter toute suppression accidentelle, une confirmation est requise avant que les fichiers sélectionnés ne soient définitivement effacés des bases de données.
- Exportation des données : L’utilisateur peut exporter les fichiers sous format CSV, que ce soit pour une sélection précise ou pour l’ensemble des données affichées. Ce format est particulièrement utile pour traiter les informations dans Excel ou tout autre logiciel de gestion de données.
Deuxième tâche - Back-end
J’ai développé la partie back-end du projet en assurant la communication entre le front-end et la base de données via des routes API. Ce travail a impliqué la définition des modèles de données, le choix des technologies de stockage et l’implémentation des services nécessaires pour garantir une gestion efficace des fichiers importés.
Modélisation des données
L’importation des fichiers repose sur une structure hybride, combinant MariaDB pour le stockage des métadonnées et ElasticSearch pour les données brutes. Cette approche permet d’assurer la traçabilité des imports tout en optimisant les performances lors des recherches et manipulations. La structure des fichiers importés suit un modèle standardisé où chaque ligne correspond à un mois comptable et à une nature d’import (Réel ou Budget).
L’implémentation de ce modèle repose sur Entity Framework Core en approche code first, ce qui permet de définir la structure directement en C# et de générer les tables correspondantes en base de données.
Entités - Import
public class Import : AbstractAuditableEntity
{
public int Annee { get; set; }
public int Mois { get; set; }
public int NbLignes { get; set; }
public string EtatImport { get; set; } = null!;
public string Nature { get; set; } = null!;
public int DomaineId { get; set; }
public int SocieteId { get; set; }
public Societe Societe { get; set; } = null!;
public Domaine Domaine { get; set; } = null!;
}
La classe
Importhérite d’une classe abstraite nomméeAbstractAuditableEntity, qui centralise les propriétés partagées entre l’ensemble des entités du modèle, telles que l’identifiant, la date de création ou encore l’utilisateur ayant réalisé l’action.
Ce modèle est ensuite intégré dans le contexte de base de données via EF Core, ce qui permet de générer automatiquement les migrations et de maintenir la structure des tables synchronisée avec le code.
Mise en place des routes API
Pour permettre l’interaction entre l’interface utilisateur et les bases de données, j’ai défini plusieurs routes API via FastEndpoints, un framework performant pour ASP.NET Core. Ces routes sont conçues pour couvrir les besoins principaux de l’application :
- Récupération des fichiers importés
- Importation et validation des fichiers
- Suppression des fichiers invalides
- Gestion des droits d’accès aux données
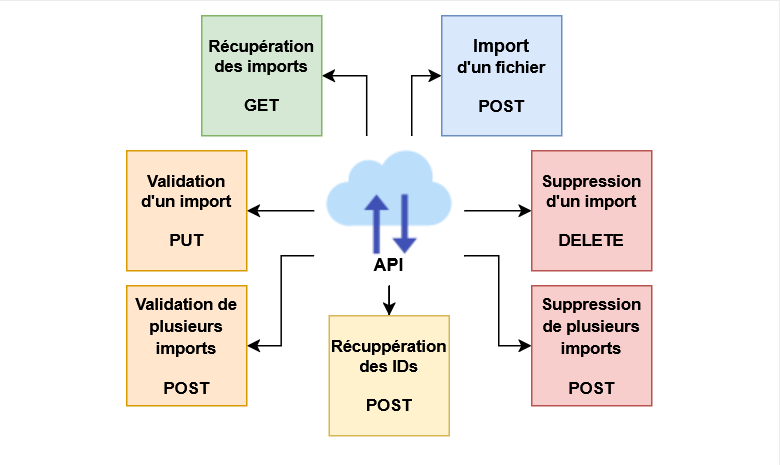
Pour sécuriser les accès aux fichiers importés, j’ai mis en place un endpoint GET permettant de filtrer dynamiquement les données en fonction de l'identité de l'utilisateur connecté. Cette logique repose sur l’intégration avec Keycloak pour l’authentification, et sur la structure des droits définie dans la base de données.
Le traitement vérifie que l'utilisateur est bien rattaché à une société autorisée avant d'exposer les données. Ce comportement conditionnel assure une couche supplémentaire de sécurité applicative, tout en rendant le système adaptable à des contextes multi-sociétés ou multi-utilisateurs.
Endpoint GET - Récupérer les imports
public override async Task HandleAsync(GetImportRequest request, CancellationToken ct)
{
int id = Route<int>("Id", true);
var utilisateurId = (await Context.Utilisateurs.FirstOrDefaultAsync(u => u.KeycloakId == request.KeycloakGuid, ct))?.Id;
var result = await Context.Imports
.Include(i => i.Societe)
.Where(i => id == i.Id
&& (!request.DomaineId.HasValue || request.DomaineId == i.DomaineId)
&& (!utilisateurId.HasValue
|| i.Societe.SocietesUtilisateurs.Any(su => su.Utilisateur.KeycloakId == request.KeycloakGuid && su.Utilisateur.Actif)))
.Select(i => Map.FromEntity(i))
.FirstOrDefaultAsync(ct);
if (result == null)
{
await SendUnauthorizedAsync(ct);
}
else
{
await SendOkAsync(result, ct);
}
}
Cette route s’appuie sur un double filtrage : par domaine fonctionnel et par appartenance de l’utilisateur à la société liée à l’import. Elle garantit que l’accès aux données est restreint aux seuls utilisateurs autorisés.
Traitement des fichiers importés
L’importation des fichiers se fait en plusieurs étapes :
- Lecture et conversion du fichier CSV en objets manipulables.
- Validation des données pour s’assurer qu’elles respectent les critères du système.
- Enregistrement des métadonnées dans MariaDB et des données détaillées dans ElasticSearch.
Le traitement des fichiers CSV repose sur un endpoint POST conçu pour être à la fois rapide et robuste. Une fois les lignes du fichier lues, elles sont distribuées à travers un traitement asynchrone et parallèle afin d’optimiser le temps de traitement sur des volumes importants.
Chaque ligne subit une phase de validation métier grâce à un validateur dédié, avant d’être convertie dans un format compatible avec ElasticSearch si elle est jugée conforme. Cette approche par segment permet de gagner en performance tout en isolant facilement les lignes problématiques.
Endpoint POST - Traitement des lignes d'imports
await Parallel.ForEachAsync(importList, ct, async (import, ct) =>
{
var validationResult = await validator.ValidateAsync(import, ct);
if (validationResult.IsValid)
{
dataList.Add(ConvertToElasticData(import, GenerateEncryptionProvider));
}
else
{
validationResult.Errors.ForEach(e => errors.Add(e.ErrorMessage));
}
});
Le traitement parallèle permet de valider chaque ligne du fichier de façon indépendante, tout en optimisant les performances. Une gestion fine des lignes en erreur est également mise en place grâce à
validationResult.Errors.ForEach(...), permettant de remonter les messages à l’utilisateur pour faciliter la correction du fichier source.
Validation et suppression des imports
Une fois importés, les fichiers doivent être validés avant d’être exploités. Une route permet de modifier leur état en "Validé" et ainsi les rendre disponibles dans le système. En cas d’erreur ou de doublon, une autre route permet de supprimer un fichier et ses données associées à la fois dans MariaDB et ElasticSearch.
Enfin, la validation manuelle des imports est un point clé du processus métier. Une fois que les données ont été vérifiées ou corrigées, une route PUT permet de changer leur statut pour les marquer comme valides, ce qui déclenche leur visibilité dans les interfaces principales.
Dans une optique de nettoyage régulier ou de gestion des erreurs, il est également possible de supprimer les fichiers non conformes via une route dédiée, garantissant ainsi la cohérence entre MariaDB et ElasticSearch, et évitant toute pollution des référentiels.
Endpoint PUT - Validation des lignes d'imports
var currentImport = await Context.Imports.FirstOrDefaultAsync(i => i.Id == id, ct);
if (currentImport != null && currentImport.EtatImport != "Validé")
{
currentImport.EtatImport = "Validé";
Context.Imports.Update(currentImport);
await Context.SaveChangesAsync(ct);
}
La validation de l’import passe ici par un simple champ de type chaîne pour en améliorer la lisibilité, mais en production ce champ est représenté par un
enum, afin d’éviter l’usage de valeurs magiques et d’assurer une meilleure robustesse du code.
Le développement de la partie back-end a nécessité une approche structurée, en combinant EF Core pour la gestion des base de données, ElasticSearch pour le stockage rapide des données volumineuses, et FastEndpoints pour la mise en place d’une API performante. La séparation des données entre MariaDB et ElasticSearch permet d’optimiser à la fois la traçabilité et les performances de recherche. Enfin, la gestion avancée des droits d’accès assure que chaque utilisateur ne visualise que les fichiers qui lui sont destinés, garantissant ainsi la sécurité et la conformité des données.
Troisième tâche - Front-end
J’ai développé la partie front-end du projet en concevant l’interface utilisateur avec Vue.js, un framework JavaScript moderne appartenant à l’écosystème des technologies Web. Ce choix nous a permis de créer une interface fluide et réactive, tout en facilitant la structuration des composants et la gestion des états.
Conformément aux maquettes fournies, j’ai assuré l’intégration des interactions avec le back-end et les API, en veillant à la cohérence visuelle et à l’ergonomie. J’ai également exploité les MétaModèles mis en place côté back-end pour automatiser une partie de l’affichage et simplifier la gestion dynamique des données dans l’interface.
Développement de l’interface
Dans la continuité du choix technologique, l’interface repose sur une architecture composants propre. De plus, pour accélérer la mise en œuvre des éléments interactifs, j’ai intégré DevExtreme, une bibliothèque UI offrant des composants performants, notamment pour les grilles de données, les graphiques et les formulaires enrichis. Cette combinaison a permis de répondre efficacement aux exigences fonctionnelles tout en garantissant une expérience utilisateur fluide et cohérente.
L’un des éléments centraux de l’interface est une grille de données affichant les fichiers importés, conçue à partir du MétaModèlesImportResponse. Ce modèle, défini dans la base de données et accessible via une API, permet d’adapter dynamiquement la structure des données affichées, sans modifier le code front-end à chaque évolution du projet.
Composant DevExtreme - Grille
<DxDataGrid
ref="myDataGrid"
:show-borders="true"
:remote-operations="{ filtering: true, sorting: true, paging: true }"
class="dataGrid_custom"
:columns="columns"
sorting-mode="multiple"
@option-changed="handlePropertyChange"
@content-ready="onContentReady"
@key-down="onKeyDown"
v-model:selection-filter="selectionFilterValue"
>
</DxDataGrid>
Le tri, le filtrage et la pagination sont délégués au serveur, ce qui améliore les performances sur de gros volumes. Le
v-modellié au filtre permet une gestion centralisée de la sélection, utile pour déclencher des actions ciblées.
Gestion des données et connexion à l’API
L’interaction avec les données importées repose sur des appels API réalisés en TypeScript, un surensemble de JavaScript offrant un typage fort et une meilleure maintenabilité du code. Les requêtes permettent de récupérer les fichiers stockés dans MariaDB, en tenant compte des droits d’accès des utilisateurs, gérés par Keycloak.
Appel API - Récupérer la liste des imports
async function fetchImports() {
return await apiClient.get<ImportResponse[]>('/api/imports');
}
Le typage
ImportResponse[]sécurise l’auto-complétion et le contrôle des structures en cas d’évolution du back. Idéalement déclenché aumounted()pour charger les données dès le rendu du composant.
Les données récupérées sont ensuite appliquées dynamiquement à la grille de données, garantissant une synchronisation en temps réel avec la base.
Gestion des actions utilisateur
L’interface intègre plusieurs boutons d’action, permettant aux utilisateurs d’interagir avec les fichiers importés (importation, validation, suppression). Ces boutons sont basés sur un composant réutilisable, configurable avec différents paramètres tels que l’icône, le nom et la fonction associée.
- L’utilisateur sélectionne un fichier via l’explorateur.
- Le fichier est vérifié pour s’assurer qu’il est au format CSV.
- Il est ensuite envoyé à l’API via TypeScript.
- L’utilisateur reçoit une notification confirmant ou non l’importation.
Cas utilisateur - Import d'un fichier CSV
async function importData(file: File) {
const formData = new FormData();
formData.append("file", file);
await apiClient.post("/api/import", formData);
}
Le fichier est encapsulé dans un objet
FormData, compatible avec les endpoints multipart côté serveur. Cette méthode simplifie l’envoi de fichiers, tout en permettant d’ajouter d’autres métadonnées si nécessaire.
Ce développement full front-end m’a permis d’intégrer une interface modulaire et évolutive, exploitant Vue.js, DevExtreme et TypeScript pour offrir une navigation fluide et une gestion optimisée des fichiers importés. Grâce aux MétaModèles, l’interface s’adapte dynamiquement aux changements de structure des données, limitant les mises à jour manuelles du code. L’ensemble des actions utilisateurs est centralisé via des composants réutilisables, garantissant performance et maintenabilité.
Quatrième tâche - DevOps
J’ai mis en place le système de stockage ElasticSearch dans TesfriX, une première pour l’équipe, qui utilisait jusqu’ici MongoDB pour le stockage de données massives. ElasticSearch a été choisi pour ses performances de recherche avancées, son intégration simplifiée et sa compatibilité avec notre architecture. Celle-ci repose sur Kubernetes, un outil d’orchestration de conteneurs Docker, qui nous permet de déployer, maintenir et faire évoluer les différents services applicatifs de manière souple et automatisée.
Avant de me lancer dans la configuration technique, j’ai pris le temps de consulter plusieurs documentations spécialisées en anglais, portant sur le déploiement d’ElasticSearch dans un cluster Kubernetes. Cette phase de recherche a été essentielle pour appréhender les bonnes pratiques, comparer différentes approches, et adapter la solution aux besoins du projet. Cela m’a permis de gagner en autonomie sur un sujet complexe, tout en assurant un déploiement robuste, maintenable et bien intégré à l’écosystème existant.
Déploiement d’ElasticSearch
L’infrastructure de TesfriX repose sur Kubernetes pour l’orchestration des services, Helm pour la gestion des configurations et ArgoCD pour l’automatisation des déploiements. Bitnami nous permet de standardiser l’installation des services via des charts Helm, facilitant ainsi leur gestion et leur mise à jour.
L’installation d’ElasticSearch a nécessité une configuration centralisée, stockée et versionnée dans Git. J’ai préparé un fichier Helm définissant les paramètres essentiels du déploiement, comme la gestion des ressources CPU/mémoire, le nombre de réplicas et la persistance des données.
Configuration Kubernetes - Fichier déploiement
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: elasticsearch
namespace: argocd
spec:
destination:
namespace: elasticsearch
server: https://kubernetes.default.svc
source:
repoURL: https://helm.elastic.co
chart: elasticsearch
targetRevision: 8.10.4
syncPolicy:
automated:
prune: true
selfHeal: true
helm:
values: |
replicas: 3
minimumMasterNodes: 2
resources:
requests:
cpu: "100m"
memory: "1Gi"
limits:
cpu: "200m"
memory: "2Gi"
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
resources:
requests:
storage: 10Gi
Le paramètre
selfHealgarantit que tout écart entre Git et le cluster sera corrigé automatiquement. Également, la réplication est activée avec 3 pods, et la persistance des données est assurée via un PVC de 10 Go.
Mise en production
Une fois les configurations finalisées, ArgoCD a été utilisé pour déployer et synchroniser ElasticSearch avec notre cluster Kubernetes. J’ai ensuite réalisé plusieurs vérifications pour m’assurer du bon fonctionnement du service :
- Vérification des pods ElasticSearch dans Kubernetes
- Tests d’accessibilité via des requêtes HTTP
- Création d’index et ingestion de données de test
Intégration d’ElasticSearch dans TesfriX
Après le déploiement, ElasticSearch a été intégré à l’application en définissant les points de connexion dans les fichiers de configuration du domaine supervision.
Configuration Kubernetes - Extrait domaine Supervision
supervision:
configuration:
ElasticSearch:
Url: "https://elasticsearch.supervision.html"
Username: "user"
Password: "password1234"
IndexName: "supervision-dev"
Les identifiants sont ici visibles à titre d’exemple, mais dans le déploiement réel, ils sont stockés de manière sécurisée dans des
Secrets.
L’installation d’ElasticSearch a renforcé les capacités de recherche et d’analyse de TesfriX, tout en s’intégrant parfaitement à notre infrastructure Kubernetes. Grâce à Helm et ArgoCD, la solution est automatisée, évolutive et facilement maintenable. L’ensemble des configurations est versionné dans Git, garantissant une gestion transparente et sécurisée des déploiements.
Résultat
À ce jour, TesfriX est pleinement opérationnel en production, utilisé quotidiennement sans rencontrer de problèmes majeurs, ce qui témoigne de la robustesse de son architecture et de la fiabilité des solutions mises en place. L’ensemble des fonctionnalités développées répond aux objectifs initiaux, garantissant une gestion fluide des imports de données, une intégration efficace avec l’API et une interface utilisateur intuitive.
Cette expérience m’a permis d’avoir une autonomie totale dans la gestion des aspects front-end et back-end du projet, consolidant ainsi mes compétences en développement logiciel et en architecture applicative. La réalisation du front-end m’a appris à transformer une maquette en une interface fonctionnelle et ergonomique, tandis que le back-end m’a permis d’optimiser les performances et d’assurer une gestion efficace des données. La collaboration en binôme pour la conception des maquettes et la recherche d'information lors du DevOps a été un atout majeur, permettant d’aligner précisément les attentes du projet avec les besoins des utilisateurs finaux, tout en garantissant la pérennité de l'application.
Si je devais améliorer certains aspects du projet, j’opterais pour l’intégration d’un système de base de données MongoDB à la place ElasticSearch, afin d’uniformiser la gestion des base de données non relationnelles au sein de TesfriX. Cette approche permettrait d’avoir une meilleure cohérence dans l’architecture globale du stockage et de faciliter la maintenance des données. De plus, une meilleure gestion des droits d’accès au niveau des imports pourrait être envisagée afin d’affiner encore davantage le contrôle des permissions sur les fichiers.
Avenir du projet
Aujourd’hui, l’objectif principal est d’intégrer l’intégralité du WMS Tesfri dans TesfriX. Cette transition représente une évolution majeure, visant à transformer TesfriX en une plateforme complète et centralisée, englobant l’ensemble des fonctionnalités historiquement gérées par Tesfri. Cela implique un travail approfondi sur l’architecture du projet, la migration des fonctionnalités existantes et l’optimisation des performances pour assurer une transition fluide et efficace. Dans cette perspective, l’accent sera mis sur la consolidation de l’infrastructure, l’amélioration continue des processus de synchronisation et la mise en place d’une gouvernance robuste des données afin de garantir une solution durable et évolutive.
Retour sur expérience
Réaliser cette partie du projet a été un véritable plaisir, tant sur le plan technique qu’humain. Pouvoir concevoir, développer et voir aboutir une solution concrète m’a apporté une grande satisfaction. Ce projet m’a permis de me challenger, d’explorer de nouvelles approches et d’approfondir mes compétences en toute autonomie, tout en collaborant efficacement avec mon équipe.
Aujourd’hui, savoir que TesfriX est utilisé quotidiennement par des utilisateurs qui s’appuient sur ce que j’ai développé est particulièrement gratifiant. Voir mon travail s’intégrer dans leur quotidien et contribuer à l’amélioration de leur productivité donne un véritable sens à tout l’investissement que j’ai pu fournir. Cette expérience m’a conforté dans l’idée que le développement logiciel ne se limite pas à écrire du code, mais qu’il a un impact direct sur les utilisateurs, ce qui rend chaque projet encore plus motivant.
Compétences liées
C# .NET - Technologie Web - Frameworks - Docker - Base de données - Maquettage - Autonomie - Travail en équipe - Anglais